I spent the last year of my undergraduate studies working on a reinforcement learning solution for my university robotics team as we prepared for the International Aerial Robotics Competition mission 7 challenge.
Mission 7 required building an autonomous aerial vehicle that would “herd” 10 Roombas across a goal line by bumping into them or landing on top of them to alter heading, while handling 4 moving obstacles on a 20x20 meter field in a GPS-denied environment within 10 minutes.

The IARC Mission 7 playfield, our autonomous quadcopter, and two modified Roombas.
My Role
The team wanted to evaluate reinforcement learning, and I researched feasibility for an end-to-end approach where observations were raw camera input and actions were target coordinates.
Approach
I used OpenAI Gym to create a training environment and started with a simplified problem: large vehicle speed advantage, no obstacles, and full field visibility. After iterating through many methods, I settled on Proximal Policy Optimization for its balance of simplicity and performance.
Simulation
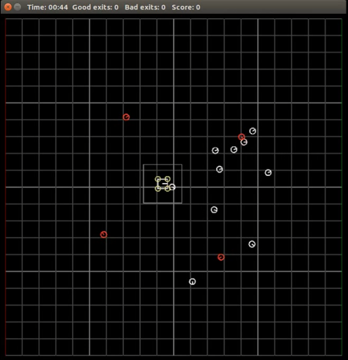
Simulation of the game. The aerial vehicle (center, boxed) interacts with goal Roombas (white circles) and herds them across the goal line on the right. Red circles are moving obstacles.
Progress
During training I learned the importance of reward engineering and added incentives beyond raw game points. The most important was a “direction incentive” that rewarded the model when the average Roomba heading pointed toward the goal line.
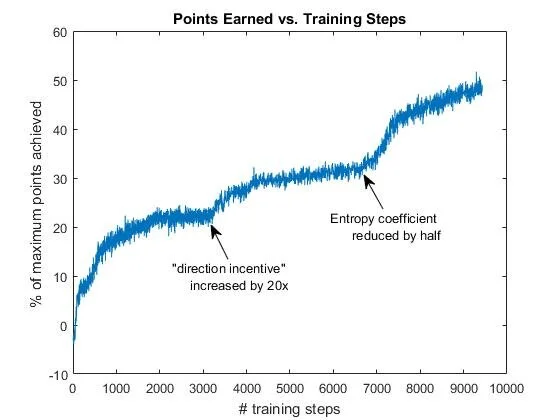
Points earned vs. Training Steps. Notice the positive progress made when doubling the “direction incentive” and when halving the entropy coefficient — a hyperparameter that regulates the exploration vs. exploitation tradeoff.
After months of hyperparameter and reward iteration, the model reached an average of roughly 75% of maximum points in the game and could play perfect runs in simulation.
Conclusion
Progress stopped when I graduated, but I felt I had successfully evaluated feasibility. My conclusion was that fully end-to-end RL was not appropriate for this system — machine learning is inherently difficult to debug — while targeted ML components could still be useful within a larger algorithmic architecture.